Will the partnership with Eclipse help OSI understand that the Open Source AI Definition fails to meet just about any open-source smell test?
Open Source Initiative and Eclipse Foundation have agreed to work together to try to get a handle on how to approach AI, especially generative AI that requires massive amounts of content to digest for machine training purposes. The announcement came on Thursday, only 2 1/2 weeks after OSI’s executive director, Stefano Maffulli announced the release of version 1.0 of the Open Source AI Definition at this year’s All Things Open conference in Raleigh.
OSI knew going in that the definition would need to evolve — hence the reason for the versioning. That need for further work is already evident in the public pushback to OSAID as it now stands.
Community Backlash Against OSAID
“It’s terrible,” security pundit Bruce Schneier penned in an article that ran on Security Boulevard on November 8. “It allows for secret training data and mechanisms. It allows for development to be done in secret. Since for a neural network, the training data is the source code — it’s how the model gets programmed — the definition makes no sense.”
Schneier opines that perhaps the good people at OSI have been listening to the wrong people, which seems to be probable:
“OSI seems to have been co-opted by industry players that want both corporate secrecy and the ‘open-source’ label,” he said. “This is worth fighting for. We need a public AI option, and open source — real open source — is a necessary component of that.”

Bruce Perens, who wrote the original Open-Source Definition, also isn’t happy with OSAID. A week or so before the release of OSAID v1.0, when a release candidate was available on OSI’s website, he said in a comment on LinkedIn, “In my opinion, the result is less than open source.”
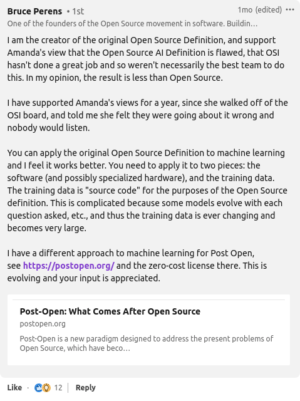
That comment was in reply to a thread that was started by Amanda Brock, a former OSI board member and the CEO of OpenUK. She said, “The Open Source Initiative have done a lot of work but I don’t agree with what’s being done. I am not alone. Most (not all) senior open-source software engineers I have spoken to agree with me. They either did not know that the OSI was doing this new definition, or like me didn’t want to speak out lest they risk us undermining the OSI.”
As I see it, the main problem is that OSAID includes training data that can’t be accessed — which means that training models can be inserted into the code as unaccessable binary blobs and still be covered under an open-source AI license. This is not something I ever expected to come out of OSI. The definition does at least require details to be included about what information is in the training data, but doesn’t require access to the data itself.
According to OSI, this is necessary because not to do so might mean that some players will forgo open source for propriety. That sort of worry is not in keeping with the open-source way.
“Some people believe that full unfettered access to all training data (with no distinction of its kind) is paramount, arguing that anything less would compromise full reproducibility of AI systems, transparency and security,” OSI explains in its FAQ on the definition. “This approach would relegate open-source AI to a niche of AI trainable only on open data. That niche would be tiny, even relative to the niche occupied by open source in the traditional software ecosystem.”

Maybe. But wouldn’t our old frenemy “open core” offer the solution of allowing proprietary training data to be inserted into an otherwise open-source system as something like a plugin? As much as I’m generally opposed to open core, that would be a better alternative than allowing non-open data to qualify as open source, which would reduce open source to a meaningless term.
The day after the definition’s release was announced, I had the chance to sit down with Tracy Hinds, OSI’s chairperson. Our conversation didn’t do much to make me feel good about OSI’s decision, and the fact that nearly every answer had something to do with workshops the board had taken, and experts and stakeholders who had been consulted caused me to think that perhaps the OSI board was overthinking things a bit. After all, if you’re an OSI board member you should pretty much already know what is or isn’t open source.
As Perens pointed out in his LinkedIn comment, you might be better off just sticking the the Open Source Definition you’ve got:
“You can apply the original Open Source Definition to machine learning and I feel it works better. You need to apply it to two pieces: the software (and possibly specialized hardware), and the training data. The training data is ‘source code’ for the purposes of the Open Source Definition. This is complicated because some models evolve with each question asked, etc., and thus the training data is ever changing and becomes very large.”
Debian developers have also expressed issues with the definition.
Will Eclipse Partnership Help or Hinder?
Bringing Eclipse in to act as something like the project’s sous-chef might or might not help get OSI on track.

On the plus side, there are thousands of developers working on the more than 400 projects that are under Eclipse’s umbrella, most of whom won’t be persuaded by attempts to move open source licensing to something that looks more like “proprietary in disguise” rather than true open source.
On the negative side, it’s the C-suite suits who write the checks that keeps the foundation afloat, and you know going in how they’ll vote.
According to the news release from OSI, the two organizations are calling their agreement a Memorandum of Understanding, and while there’s little in the scant details that have been released to give me hope that this might move OSI away from applying something that sounds like a Microsoft or Oracle inspired definition of open source, there’s also nothing there to tell me it won’t.
According to OSI, “The MoU outlines several areas of cooperation, including:”
- “Information Exchange: OSI and the Eclipse Foundation will share relevant insights and information related to public policy-making and regulatory activities on artificial intelligence.
- Representation to Policymakers: OSI and the Eclipse Foundation will cooperate in representing the principles and values of open source licences to policymakers and civil society organisations.
- Promotion of Open-Source Principles: Joint efforts will be made to raise awareness of the role of open source in AI, emphasizing how it can foster innovation while mitigating risks.”
My conversation with Hinds did offer some indication that with this first “stable version” of OSAID, the OSI board is taking the pasta approach and throwing something against the wall, and that everything is still subject to change depending on whether or not it sticks.

“The idea is that it is 1.0,” she said. “It is a reference point for researchers, for developers, for policy makers to go in and say, here’s where the cracks are… or this totally works for us, how do we build off of this towards the next steps that we actually need to implement it? How do we write an AI license if we don’t have those components defined?”
Wiggle room, in this case, might be a good idea.
Christine Hall has been a journalist since 1971. In 2001, she began writing a weekly consumer computer column and started covering Linux and FOSS in 2002 after making the switch to GNU/Linux. Follow her on Twitter: @BrideOfLinux



