Can you hear me now?
The question, if it’s presented with early 21st century pop culture in mind, is rhetorical. If you are relying on text to speech (TTS) applications in Linux, then it’s not…and the answer is no.
No, you cannot hear me now.
I chose to have my larynx removed during the second week of January in order to insure the cancer in my throat would not return. It’s now highly unlikely, but in making that decision I faced the fact that I would no longer be able to communicate spontaneously with others. I would need to rely upon one device or another, but more often than not, a combination of those devices.
 I will not use an electrolarynx or any derivative thereof.
I will not use an electrolarynx or any derivative thereof.

At the age of eleven I was frightened terribly by someone talking to my uncle while I stood beside him. It frightened me so much that I ran outside and sat in the car, refusing to go back inside. And sure, most kids won’t have my reaction, but I’m going to insure than no one has that reaction…at least when I speak to them.
But there are other options. One of them I lean strongly toward is text to speech. There are many online tools to accomplish this, and you can see a good example on the From Text to Speech website. Just type in what you want to be said, choose the voice you want to represent your voice and click the play icon. You can even save what you say as an mp3 file. The voices provided by this website are good, but if you are going to compare them to the voices encountered by default in most Linux applications, the difference is glaring.
Let’s talk about those Linux apps.
When I first decided that I wanted to use text to speech on a daily basis, I began researching and testing the available applications. The Mint/Ubuntu repositories showed much promise. The first thing I did was become acquainted with the KDE app Jovie. It’s appeal was that it’s built to work right in KDE, but right out of the gate I ran into a such a high level of complexity and gaping holes in usability that I just shut it down and began searching for other solutions. Apparently, Jovie depends on other voice “synthesisers” to get working.
Really? Why isn’t it an all in one package? Surely there has to be a better tool for the job. I’m not incompetent when it comes to getting stuff on a computer to work. I’ve used Linux long enough to know that complexity will be necessary from time to time. But what I don’t have enough of is time. So I moved on to see what else was out there.

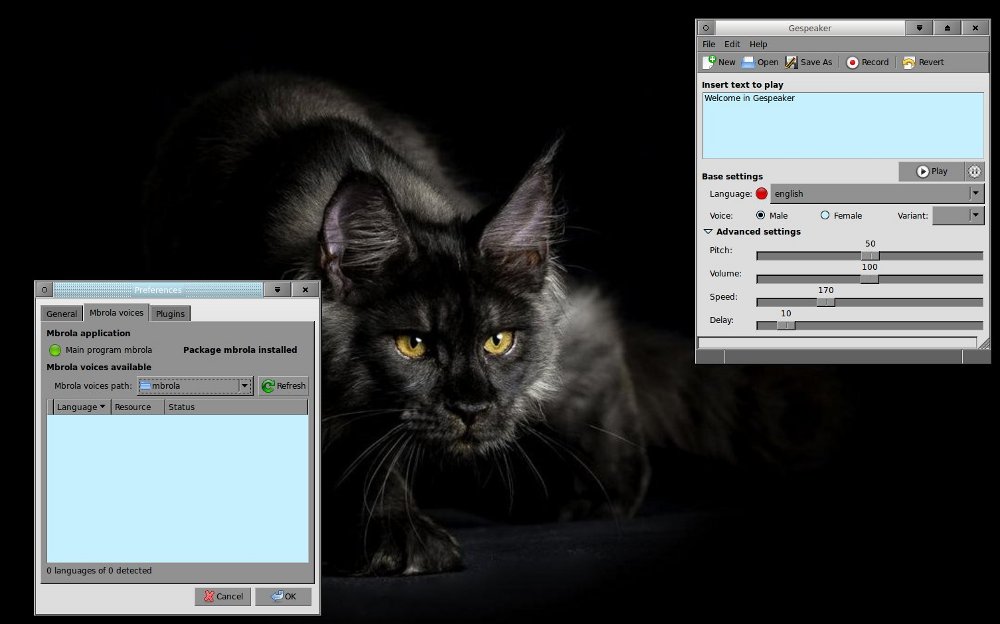
Ah, I see we have a dynamic duo of sorts to work with here. We have TTS, the text to speech program that acts as a front end from which to work, such as Gespeaker. You then have your speech engines like like Mbrola and eSpeak to draw the synthesis from. OK, so it’s gonna be like this for all the Linux TTS offerings, huh? Well crap, if that’s what I have to do, let’s see which is easiest.
I chose Gespeaker because, if for nothing else, it seemed the least complicated. In retrospect, that’s too funny.
I get into Gespeaker and it seems fairly intuitive. It wants me to pick a voice from Mbrola in order to work. Okay…the GUI is telling me that Mbrola is installed. It even guides me to .deb files from which to install a choice of several voices. So I am going to choose the US 1 male voice. Uh, it should be playing the stuff I type in that US 1 male voice, but it’s not. It’s still speaking like Mr. Roboto. Well poop, let me see what I can find. The voices seem to be in the correct directories.
But they are not. In fact, in researching it I discover there has been a running gun battle about these voices and the proper file paths from as far back as 2010…maybe 2008, if I remember correctly. Really? So who’s the moving target. Who is changing these things without proper documentation. Well, first off, let’s see what the developers of Mbrola have to say as to what it does and how it does it, in Synaptic:
“Multilingual software speech synthesizer
Mbrola is Thierry Dutoit’s phonemizer for multilingual speech synthesis. The various diphone databases are distributed on separate packages, but they must be used with and only with Mbrola because of license matters. Read the copyright for details.
Mbrola itself doesn’t provide full TTS. It is a speech synthesizer based on the concatenation of diphones. It takes a list of phonemes as input, together with prosodic information (duration of phonemes and a piecewise linear description of pitch), and produces speech samples on 16 bits (linear), at the sampling frequency of the diphone database.
Use Mbrola along with Freephone, cicero or espeak to have a complete text-to-speech in English.”
Oh yeah…I was looking into getting my speech synthesized based on the concatenation of my diphones anyway. This is why I, and many other Linux advocates, have suggested that developers leave the PR and product documentation to others.
But seriously, the state of text to speech in the Linuxsphere is a mess.
It’s funny. I will be attending the LibrePlanet 2015 event this year and I will be talking about how important free and open source software is to Reglue. Without it, we would not exist. I find it mildly ironic that I might be making that presentation from an iPad.
My G+ buddy Charlie Kravetz spoke at SCALE just days ago and made serious mention of these problems. There is a collaboration site which I moderate that deals with nothing but trying to figure out the best ways to bring easy to use and inexpensive AAC applications to those who need them. In fact, if the stars align just right, we’ll see you at OSCON to discuss just this topic. Because at this time, those applications do not exist for Linux, at least not those that take less than five days to mess with and still not get working.
Many of you will perceive this as an attack on the various developer of TTS software. Quite the opposite. It’s an appeal to get others interested in picking up where they have left off. It’s apparent that the developers of these various software applications have scratched their itch and walked away. They wrote the software to meet their needs and freely gave their efforts to anyone to alter in any way they see fit. For that, I offer my personal and sincere thanks. You’ve paved the road so as to make the world an easier place to live.

But what of those to come? What of those who cannot speak, or hear…or see. Those who couldn’t tell you the difference between the front end and the back end of any software if it hit them in the ass with a boat paddle?
There are a lot of us out here. There are a lot of us who will finally realize that in many cases, Linux is not the be all and end all to computing. Of course, many of us already know that. I guess that’s what maturity brings.
Ken Starks is the founder of the Helios Project and Reglue, which for 20 years provided refurbished older computers running Linux to disadvantaged school kids, as well as providing digital help for senior citizens, in the Austin, Texas area. He was a columnist for FOSS Force from 2013-2016, and remains part of our family. Follow him on Twitter: @Reglue




Ken:
I was gratified to read of your criticism of geek writing PR and instructions. I have tried to tell the Thunderbird and Firefox people at least that if they would stop trying to solve problems in forums and FAQ’s themselves and go to someone who is capable of explaining things, their market share would zoom up. I am not a Linux geek and every time I read about a fix that involves some weird programming inserted into something somewhere (they never say where to actually put it) my eyes glaze over, I go into “I’ll just have to endure it” mode and I learn to live with my problem. My favorite candidate is Leo Notenboom (askleo.com) who could explain pollen tracking to a bumble bee. He is just that good at explaining (I’m no relation, just an admirer). Get Leo to head up your customer service team or at least learn from him.
Something has to change in the FOSS community. The complexity of problem solving is unmanageable (Mozilla’s initial introduction to Firefox is a great exception). And I always grit my teeth when asked to register before I can even ask a question. I hate that! The people are good at quickly responding but the geekiness is soooo offputting.
As someone who doesn’t /have/ to use such tools, but who has in my proprietaryware past found them interesting to play with, and who appreciates the necessity they can be for some and thus who would dearly love for them to “just work” on Linux… but who has never quite found the time to do what you’re finding necessary…
Perhaps, Ken, this is the next windmill you’re supposed to tilt at and set spinning… I mean that. You have a way of getting things moving and have been blessed with an outsized “voice” to do it with, and if there’s one other area I’d name that could use the same sort of effective voice getting things moving that has kept Helios and now Reglue going, this is surely it. As you mention, the technical bits are pretty much there, and it seems there’s people wanting to help; they just need someone with an outsized voice to speak for them and for the people that need them, to get things moving and get all those volunteers and available resources coordinated into a team all pulling in the same direction /as/ a team. And if I were to name one person I thought could do it… it’d be you.
So go to it, Ken. Your work here on earth isn’t done just yet! =:^)
And… thanks… from all of us, those who need it, and those who would just find it fun to play with. =:^)
Duncan
Hi Ken. I know what you are talking about. I have helped a couple of blind friends with text-to-speech and screen readers for several years now. It is really too bad that no one has pulled the various components together in a relatively easy to use system for Linux. Screen readers/speech synthesizers for Windows are just too expensive, and don’t work as well as they really should.
Keep speaking out through your blogs!
I do not claim any particular knowledge or expertise with TTS software on any platform, but after reading what you wrote here, it made me think of something I recently saw on Planet KDE.
http://jpwhiting.blogspot.com/2015/02/qtspeech-progress.html
He agrees with your basic assessment of jovie and apparently KDE and QT are working to address this limitation. It is, of course, still a valid critique to say that this should have been fixed long ago, but at least there are developers who want to address the problem.
Ken – someone with your position in the community could be a strong advocate for getting these technologies easier to use and more integrated across desktops.
This actually sounds like a good project idea for undergraduate (or graduate) credit. Could the Reglue kids in college/uni reach out to their peers for help?
Ken – you might want to mail Samuel Thibault or another visually impaired developer. They must have this problem all the time.
All the very best, as ever,
AndyC
Interesting post and replies. A cancer sufferer myself(not throat) I sympathise:)
Not a perfect solution, but workable in Linux. I’ve added the Firefox extension “Float Notes” along with “Automatic Text Reader”. The notes program allows you to add what you want rendered to speech. Right-click it, and select from the drop-down window, “speak selected text” Very understandable if you adjust the preferences to the male US Ethan. So, this I’m sure is not as good as commercial TTS programs, but does work and sounds OK with good speakers (not the awful synthesizer voice.)
Ken:
I had some fun a while back messing around with Espeak, using extremely simple BASH scripts.
The options allow a fair bit of customization, esp. with male voices.
This all worked really well for me right out of the box on my Debian 5.0 computer.
It might be possible to make this work on the fly.
Feel free to email me if you have any further questions.
>>>>>
#!/bin/sh
# enter, ctrl-d after input
# you can comment and uncomment one liners
# writes to a .wav file
espeak -v en-wi -a 20 -p 25 -s 80 -w /home/don/espeak5.wav “you have
reached 7 8 0 , please leave a message”
# just speaks it
espeak -v en-sc -a 20 -p 25 -s 90 “greetings, you have reached,
1, 7 8 0: please leave a message”
Mbrola is not even FOSS.
I tried shortly a program called festival. It’s a simple command line program: just run it, type into the terminal and press enter. It was a few years ago so I don’t remember how the voice sounded like, but I think it wasn’t that bad.
It’s in Debian. Along with the program you’ll want to install some voice package, they’re called festvox-*
I hope that can be useful for you.
On reading of your difficulty I decided to try to get working tts on my machine.
I installed speex, mbrola, festival, fetival-freebsoft-utils, jovie and KMouth.
On starting KMouth, I was asked to choose a command for speeking text, which i set to /usr/bin/festival –tts .
The KMouth frontend now speaks for me, though the voice seems a bit robotic.
Sorry for the second reply, but on starting jovie, I found that I could set different voices and adjust the speed, volume and pitch.
KMouth now sounds a lot more pleasant.
Best of luck.
Sir,
I, too, live in Austin, TX. How can I help? I was a software developer geek until retirement. Now, I’m a business and technical writer. I would welcome the opportunity to work on documentation and supporting prose for any Linux projects you identify as needing help. Further, I might also be able to offer other technical services to text-to-speech projects.
~~~ 0;-Dan
Dan, I got swamped with a number of things and I apologize for just now getting back to you. ken at reglue dott orgg will get to me.